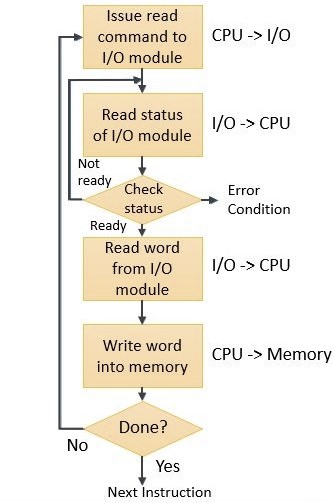
Database
A database is an organized data collection such that it is accessible, maintained, and updated simply. Computer databases normally include data or file aggregations, information on selling transactions, or customer interactions.
The digital information on a certain client in a relational DB has arranged into indexed rows, columns, and tables. So that relevant information may easily found through SQL or NoSQL queries. A graph DB , by contrast, employs nodes and edges to establish connections between information inputs and queries that need a unique semantic search vocabulary. SPARQL has the only semantic query language accepted by the World Wide Web Consortium (W3C).
Users often have the option of checking read/write access, specifying reporting, and analyzing use via the DB manager. Some databases offer ACID compliance to make sure that data are consistent and transactions complete (atomicity, consistency, insulation, and durability).
Types of database
Since their foundation in the 1960s databases has developed from hierarchical. Network databases to object-based databases in the 1980s, to SQL, NoSQL, and cloud databases.
Bibliographic, full-text, numeric, and pictures can categorize according to the kind of material from one perspective. In computers, their organizational style sometimes classifies databases. The most common method, relational databases, distributed databases, cloud databases, graph databases, or NoSQL databases are all distinct types of databases.
Relational database
Invented at IBM by E.F. Codd in 1970, a relational database has a table DB in which data have defined to rearranged and retrieved for a variety of purposes.
A number of tables containing data that fall into the designated category have formed related databases. Each tab has at least one data category in each column. For the categories set forth in the columns, each row includes some data instance.
Structured Query Language (SQL) is the default user interface for relational databases. Relational databases have easy to expand. Additional databases may added without requiring you to alter any apps. Once you have created the first DB .
Distributed database
A distributed database is a database that stores sections of the DB in a number of physical places and disperses and replicates the processing between several points in a system.
Homogeneous or heterogeneous datasets might distributed. All physical sites within a single, distributed database system have equipped with the same underlying hardware and operate the same operating systems and applications. Each location may have various hardware, operating systems, or database software in the heterogeneous distributed database.
Cloud database
A cloud-based database is an optimized or constructed database on a hybrid cloud, public cloud, or private cloud for a virtualized environment. Cloud databases offer advantages. Such as the option to pay-per-use for storage capacity and bandwidth. Offer high availability and scalability on request.
A cloud database also allows companies to enable business applications. With the deployment of software as a service.
NoSQL
For big collections of dispersed data, NoSQL databases are beneficial.
For Big Data performance problems, NoSQL databases are efficient to resolve relation databases. They have best done when a company has to examine huge portions of unstructured information or data stored in the cloud over several virtual servers.
Object-oriented
Object-oriented programming languages frequently store things in relational databases, while object-oriented databases are suitable for such objects.
An object-oriented database has organized around objects, not activities, and not logic. A multimedia record in a relational database might for example, instead of an alphanumeric value, be a defined data object.
Graph database
A NoSQL database type that employs graph theories to store, map, and query connections is a graph-oriented database or graphical database. Graph databases are fundamentally node and edge collections, where each node represents a whole and each edge constitutes a link between nodes.
The popularity of graph databases for the analysis of linkages is rising. For instance, corporations might utilize a graph database to collect data about social media consumers.
SPARQL, a declarative language of programming and protocol for graph database analysis has commonly used by graph databases. SPARQL can do all the analytics that SQL can do and can used to analyze relations, semantical analyses, and analyses. This makes it helpful for analyses of both organized and non-structured data sources. SPARQL enables users to analyze information held in the relationships and Friend of a Friend (FOAF), PageRank, and Shortest route information in a relational database.
Advantages
1. Improved data sharing: The DBMS creates an environment in which end users have greater and better-managed access to more information.
Such access allows end-users to swiftly adapt to environmental changes.
2. Improved data security: The more the dangers of data security violations, the more people access data. Corporations devote significant time, effort, and money to guarantee the correct use of business data.
A DBMS offers a framework for improved privacy and security enforcement of data.
3. Better data integration: Enhanced access to well-managed data supports an integrated perspective and a sharper understanding of the company’s activities.
How activities in one area of the business influence other segments are much simpler to discern.
4. Minimized data inconsistency: Incompatibility of the data occurs when multiple versions of the same data emerge at separate locations.
For example, data discrepancy occurs when a company sales department has “Bill Brown” as its sales representative, and the staff department of the company stores “William G. Brown” as the same person, or the regional sales department has a price of $45.95 as the regional sales bureau of the company and the national sales department has the same price as $43.95.
In a correctly constructed database, the chance of data incoherence is significantly minimized.
5. Improved data access: The DBMS enables fast replies to ad hoc requests.
For the database, an inquiry is a specific request for data manipulation given to the DBMS, for instance for reading or updating the information. Just stated, a question is a matter, and an ad hoc question is a matter of the present.
The DBMS returns a response to the application (called the query results set).
End users, for instance.
Disadvantages
1. Increased costs: Database systems demand highly experienced individuals and complex software and technology.
The costs of maintaining a database-hardware, system software, and staff can be significant. When database systems are installed, training, licensing, and regulatory compliance expenses are sometimes ignored.
2. Management complexity: Database systems demand highly experienced individuals and complex software and technology.
The costs of maintaining a database-hardware, system software, and staff can be significant. When database systems are installed, training, licensing, and regulatory compliance expenses are sometimes ignored.
3. Maintaining currency: You must maintain your system up to date to optimize the efficiency of your database system.
Thus, you must often update and apply all components with the newest patches and security measures.
Due to constantly advancing database technology, staff training expenses tend to be high. Dependency of the seller.
Due to substantial investment in technology, organizations may be unwilling to shift providers of databases.
4. Frequent upgrade/replacement cycles: DBMS manufacturers often add new functions to improve their systems. Often these new features are grouped into new software upgrades.
Some versions of these need modifications to the hardware. It costs not only money to upgrade, but also money for the training of users and administrators in using and managing the new features.